DATA CLEANING & EDA
Understanding the Structure and Quality of Raw Data
Raw data often behaves like irregular, noisy lines—full of variation, inconsistencies, and hidden patterns.
The purpose of Data Cleaning and Exploratory Data Analysis is to transform this initial chaos into meaningful information. Through structured preprocessing, anomaly detection, and visual exploration, I uncover trends, relationships, and data quality issues that shape the rest of the analytical process.
This section presents my approach to understanding a dataset before deeper modeling or business decision-making begins.

Turning raw, messy data into clarity, structure, and insight.
Before any model can learn, before any dashboard can inform, the data itself must speak clearly. In these projects, I explore the journey from unrefined, inconsistent datasets to clean, structured information ready for analysis. Using Python’s data ecosystem—Pandas, NumPy, Matplotlib, and Seaborn—I uncover patterns, resolve inconsistencies, handle missing values and outliers, and build a deep understanding of each dataset.
This collection brings together hands-on explorations of messy datasets, univariate and multivariate analysis, and custom visualizations. Each project reflects the essential early steps of data science: asking the right questions, discovering relationships, and transforming raw data into meaningful stories. It’s the foundation that enables every insight, model, and decision that follows.
Related Projects
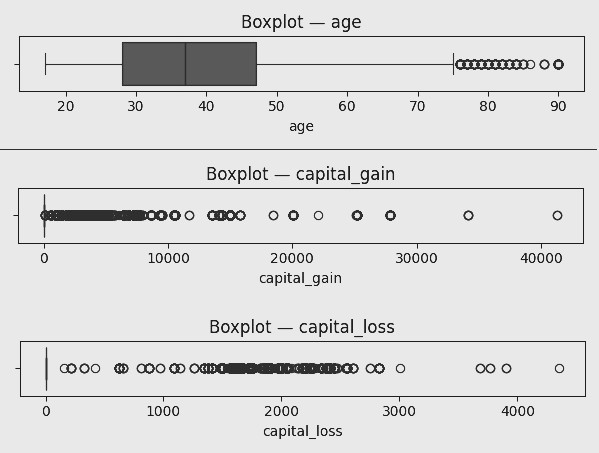
Public Survey Data
This project focuses on cleaning and preparing a real-world survey dataset — the Adult Income Dataset — often used for income classification tasks. The dataset contains information such as age, education level, occupation, and marital status, and is frequently used in predictive modeling to determine whether a person earns more than $50K per year.

NYC Taxi Trip Data
This project performs exploratory data analysis and data cleaning on the NYC Taxi Trip dataset. The goal is to discover insights into ride patterns, fare structures, and temporal trends, and to prepare clean data for modeling.
